因为踩坑ctrl-c无法退出multiprocessing pool问题,趁机简单解读一下相关代码
逻辑图
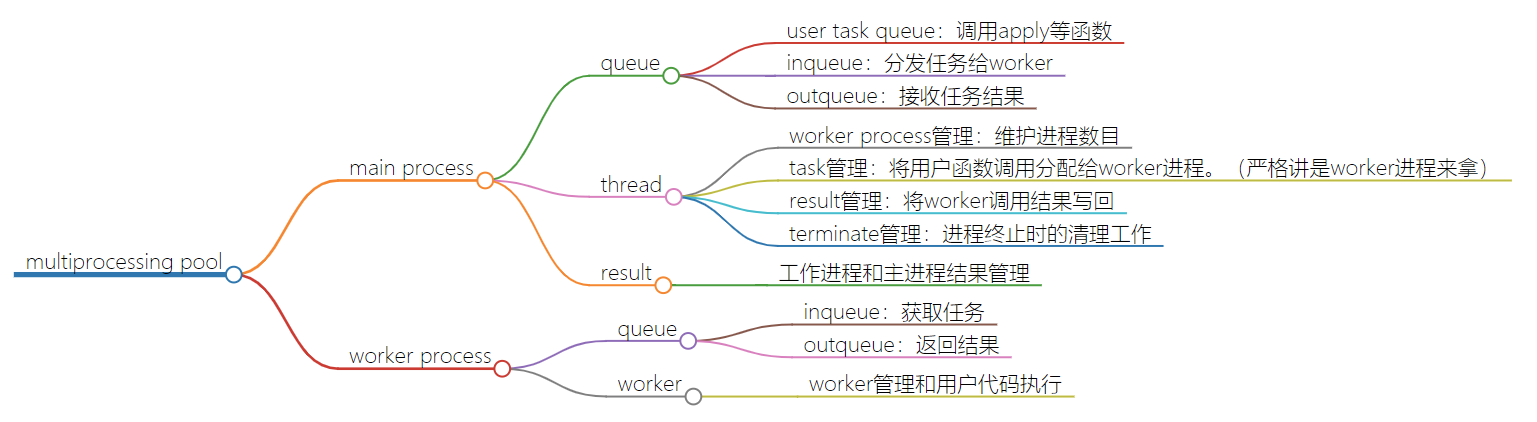
逻辑架构
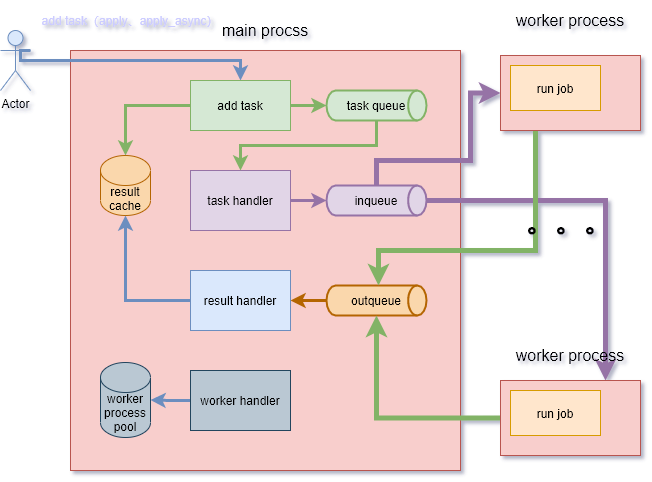
代码解读
初始化逻辑流程
- 初始化和子进程交互的队列
- 初始化存放用户任务的队列
- 初始化子进程
- 启动进程管理线程
- 启动任务管理线程
- 启动结果管理进程
- 设置清理逻辑
class Pool
class Pool(object):
'''
Class which supports an async version of the `apply()` builtin
'''
Process = Process
def __init__(self, processes=None, initializer=None, initargs=(),
maxtasksperchild=None):
# 初始化和worker进程进行交换数据的队列。是对Pipe的一层封装
self._setup_queues()
# 初始化用户任务队列,用来存放用户的任务调用信息,由apply等方法放入
self._taskqueue = Queue.Queue()
# 用来存放job和对应结果。
self._cache = {}
# 记录当前或者说下一步要进入的状态
self._state = RUN
# worker处理多少任务后销毁,创建新的进程
self._maxtasksperchild = maxtasksperchild
self._initializer = initializer
self._initargs = initargs
if processes is None:
try:
processes = cpu_count()
except NotImplementedError:
processes = 1
if processes < 1:
raise ValueError("Number of processes must be at least 1")
if initializer is not None and not hasattr(initializer, '__call__'):
raise TypeError('initializer must be a callable')
# 进程数量,进程池
self._processes = processes
self._pool = []
# 初始化进程池
self._repopulate_pool()
self._worker_handler = threading.Thread(
target=Pool._handle_workers,
args=(self, )
)
self._worker_handler.daemon = True
self._worker_handler._state = RUN
self._worker_handler.start()
self._task_handler = threading.Thread(
target=Pool._handle_tasks,
args=(self._taskqueue, self._quick_put, self._outqueue,
self._pool, self._cache)
)
self._task_handler.daemon = True
self._task_handler._state = RUN
self._task_handler.start()
self._result_handler = threading.Thread(
target=Pool._handle_results,
args=(self._outqueue, self._quick_get, self._cache)
)
self._result_handler.daemon = True
self._result_handler._state = RUN
self._result_handler.start()
self._terminate = Finalize(
self, self._terminate_pool,
args=(self._taskqueue, self._inqueue, self._outqueue, self._pool,
self._worker_handler, self._task_handler,
self._result_handler, self._cache),
exitpriority=15
)
worker管理线程逻辑:_handle_workers
它的作用是维护保持进程数量,清理死掉的子进程,拉起新的进程。
这里要注意的是,如果pool仅仅是close掉了,那么pool中剩余的任务仍然会被执行,并且全部有了结果才会退出这个线程。
为什么说是有了结果而不是说worker退出呢,因为如果子进程执行用户代码遇到了没有捕捉到的异常,那么那个用户任务的结果就无法正常设置成功。
这个维护进程就永远无法退出,直到用户调用pool.terminate()
_handle_wokers
# 清理死掉的子进程
def _join_exited_workers(self):
"""Cleanup after any worker processes which have exited due to reaching
their specified lifetime. Returns True if any workers were cleaned up.
"""
cleaned = False
for i in reversed(range(len(self._pool))):
worker = self._pool[i]
if worker.exitcode is not None:
# worker exited
debug('cleaning up worker %d' % i)
worker.join()
cleaned = True
del self._pool[i]
return cleaned
# 拉起新的子进程,保持进程数为pool大小的数量
def _repopulate_pool(self):
"""Bring the number of pool processes up to the specified number,
for use after reaping workers which have exited.
"""
for i in range(self._processes - len(self._pool)):
w = self.Process(target=worker,
args=(self._inqueue, self._outqueue,
self._initializer,
self._initargs, self._maxtasksperchild)
)
self._pool.append(w)
w.name = w.name.replace('Process', 'PoolWorker')
w.daemon = True
w.start()
debug('added worker')
def _maintain_pool(self):
"""Clean up any exited workers and start replacements for them.
"""
if self._join_exited_workers():
self._repopulate_pool()
# 维护入口。如果只是close了pool,那么pool里面现存的任务执行完成后才会结束
# 结束后放None到task队列,通知任务管理进程退出
@staticmethod
def _handle_workers(pool):
thread = threading.current_thread()
# Keep maintaining workers until the cache gets drained, unless the pool
# is terminated.
while thread._state == RUN or (pool._cache and thread._state != TERMINATE):
pool._maintain_pool()
time.sleep(0.1)
# send sentinel to stop workers
pool._taskqueue.put(None)
debug('worker handler exiting')
任务管理线程:_handle_tasks
将用户放入的task,转入到子进程监听的队列中。核心就是迭代task queue获取用户任务,然后put到outqueue中。这里之所以代码稍微复杂,是为了统一转化apply、map、imap等函数放任务的格式
_handle_tasks
@staticmethod
def _handle_tasks(taskqueue, put, outqueue, pool, cache):
thread = threading.current_thread()
# 从taskqueue中获取数据
# 数据格式 ([(job, job index|None, func, args, kwargs)], set_length|None)
for taskseq, set_length in iter(taskqueue.get, None):
task = None
i = -1
try:
for i, task in enumerate(taskseq):
if thread._state:
debug('task handler found thread._state != RUN')
break
try:
put(task)
except Exception as e:
job, ind = task[:2]
try:
cache[job]._set(ind, (False, e))
except KeyError:
pass
else:
if set_length:
debug('doing set_length()')
set_length(i+1)
continue
break
except Exception as ex:
job, ind = task[:2] if task else (0, 0)
if job in cache:
cache[job]._set(ind + 1, (False, ex))
if set_length:
debug('doing set_length()')
set_length(i+1)
finally:
task = taskseq = job = None
else:
debug('task handler got sentinel')
try:
# tell result handler to finish when cache is empty
debug('task handler sending sentinel to result handler')
outqueue.put(None)
# tell workers there is no more work
debug('task handler sending sentinel to workers')
for p in pool:
put(None)
except IOError:
debug('task handler got IOError when sending sentinels')
debug('task handler exiting')
结果处理线程:_handle_result
这里逻辑很简单,单纯的从outqueue中获取子进程的处理结果,将结果设置到对应pool._cache的AsyncResult中。
最后对outqueue的read是为了防止_handle_task线程因block无法退出
_handle_result
@staticmethod
def _handle_results(outqueue, get, cache):
thread = threading.current_thread()
while 1:
try:
task = get()
except (IOError, EOFError):
debug('result handler got EOFError/IOError -- exiting')
return
if thread._state:
assert thread._state == TERMINATE
debug('result handler found thread._state=TERMINATE')
break
if task is None:
debug('result handler got sentinel')
break
job, i, obj = task
try:
cache[job]._set(i, obj)
except KeyError:
pass
task = job = obj = None
while cache and thread._state != TERMINATE:
try:
task = get()
except (IOError, EOFError):
debug('result handler got EOFError/IOError -- exiting')
return
if task is None:
debug('result handler ignoring extra sentinel')
continue
job, i, obj = task
try:
cache[job]._set(i, obj)
except KeyError:
pass
task = job = obj = None
if hasattr(outqueue, '_reader'):
debug('ensuring that outqueue is not full')
# If we don't make room available in outqueue then
# attempts to add the sentinel (None) to outqueue may
# block. There is guaranteed to be no more than 2 sentinels.
try:
for i in range(10):
if not outqueue._reader.poll():
break
get()
except (IOError, EOFError):
pass
debug('result handler exiting: len(cache)=%s, thread._state=%s',
len(cache), thread._state)
用户api:apply_async
这里只看一个apply_async函数,其他函数大同小异。
这个函数就是简单的将用户任务构造成task的格式,放入task队列。然后返回ApplyResult给用户,作为获取结果的桥梁
def apply_async(self, func, args=(), kwds={}, callback=None):
'''
Asynchronous equivalent of `apply()` builtin
'''
assert self._state == RUN
result = ApplyResult(self._cache, callback)
self._taskqueue.put(([(result._job, None, func, args, kwds)], None))
return result
worker
worker代码是通过Popen的方式在子进程中运行的。因此我们的function(也就是task)写的时候必须牢记,自己的代码是运行中另一个进程中的。并且这个进程正常情况会一直运行下去,除非设置了maxtasksperchild参数。
worker逻辑也很清晰:
- 执行用户自定义的初始化逻辑。
- 然后进入任务循环。
- 从inqueue获取任务。
- 执行用户代码逻辑。
- 将结果放入outqueue。
worker
def worker(inqueue, outqueue, initializer=None, initargs=(), maxtasks=None):
assert maxtasks is None or (type(maxtasks) in (int, long) and maxtasks > 0)
put = outqueue.put
get = inqueue.get
if hasattr(inqueue, '_writer'):
inqueue._writer.close()
outqueue._reader.close()
if initializer is not None:
initializer(*initargs)
completed = 0
while maxtasks is None or (maxtasks and completed < maxtasks):
try:
task = get()
except (EOFError, IOError):
debug('worker got EOFError or IOError -- exiting')
break
if task is None:
debug('worker got sentinel -- exiting')
break
job, i, func, args, kwds = task
try:
result = (True, func(*args, **kwds))
except Exception, e:
result = (False, e)
try:
put((job, i, result))
except Exception as e:
wrapped = MaybeEncodingError(e, result[1])
debug("Possible encoding error while sending result: %s" % (
wrapped))
put((job, i, (False, wrapped)))
task = job = result = func = args = kwds = None
completed += 1
debug('worker exiting after %d tasks' % completed)
ApplyResult
用户获取执行结果的桥梁。
需要注意的是,如果调用get或者wait不加超时时间,那么进程就会一直block住,直到result被设置。此时无法响应signal。这是python2设计的一个bug,但是并不打算修复。详情:threading.Condition.wait() is not interruptible in Python 2.7
这里就是容易导致进程不响应
ctrl-c的地方之一。方案有以下几种
- get添加超时时间
- 保证子进程能正常退出。一般是子进程忽略相关signal
- 找个合适的途径调用pool.terminate
class ApplyResult
class ApplyResult(object):
def __init__(self, cache, callback):
self._cond = threading.Condition(threading.Lock())
self._job = job_counter.next()
self._cache = cache
self._ready = False
self._callback = callback
cache[self._job] = self
def ready(self):
return self._ready
def successful(self):
assert self._ready
return self._success
def wait(self, timeout=None):
self._cond.acquire()
try:
if not self._ready:
self._cond.wait(timeout)
finally:
self._cond.release()
def get(self, timeout=None):
self.wait(timeout)
if not self._ready:
raise TimeoutError
if self._success:
return self._value
else:
raise self._value
def _set(self, i, obj):
self._success, self._value = obj
if self._callback and self._success:
self._callback(self._value)
self._cond.acquire()
try:
self._ready = True
self._cond.notify()
finally:
self._cond.release()
del self._cache[self._job]
AsyncResult = ApplyResult # create alias -- see #17805
pool.close
close的行为就是单纯的设置pool的状态为close。 此时pool不再接受新的任务。现存的任务仍然会被继续执行
调用close后,执行join也会触发
condition.wait。此时也会block进程,无法处理signal
def close(self):
debug('closing pool')
if self._state == RUN:
self._state = CLOSE
self._worker_handler._state = CLOSE
pool.terminate
设置状态,调用_terminate
def terminate(self):
debug('terminating pool')
self._state = TERMINATE
self._worker_handler._state = TERMINATE
self._terminate()
_terminate是一个callable的Finalize对象。这个对象通过weakref绑定进程对象。在对象被销毁或者调用Finalize的时候执行pool._terminate_pool
self._terminate = Finalize(
self, self._terminate_pool,
args=(self._taskqueue, self._inqueue, self._outqueue, self._pool,
self._worker_handler, self._task_handler,
self._result_handler, self._cache),
exitpriority=15
)
_terminate_pool:
_terminate_pool
@classmethod
def _terminate_pool(cls, taskqueue, inqueue, outqueue, pool,
worker_handler, task_handler, result_handler, cache):
# this is guaranteed to only be called once
debug('finalizing pool')
# 设置pool的状态为TERMINATE,这样task线程和worker线程在有任务的(pool._cache不为空)情况下依然会退出
worker_handler._state = TERMINATE
task_handler._state = TERMINATE
debug('helping task handler/workers to finish')
# 在task线程存活的情况下,清理inqueue,确保子进程不要收到新的任务
cls._help_stuff_finish(inqueue, task_handler, len(pool))
assert result_handler.is_alive() or len(cache) == 0
result_handler._state = TERMINATE
# result handler收到None后会退出result处理循环
outqueue.put(None) # sentinel
# We must wait for the worker handler to exit before terminating
# workers because we don't want workers to be restarted behind our back.
debug('joining worker handler')
if threading.current_thread() is not worker_handler:
# 等待work handler线程退出。此处加上超时时间,避免无法处理signal
worker_handler.join(1e100)
# Terminate workers which haven't already finished.
if pool and hasattr(pool[0], 'terminate'):
debug('terminating workers')
for p in pool:
if p.exitcode is None:
p.terminate()
debug('joining task handler')
if threading.current_thread() is not task_handler:
# 等待task线程接收到None退出执行循环
task_handler.join(1e100)
debug('joining result handler')
if threading.current_thread() is not result_handler:
# 等待result线程接收到None退出执行循环
result_handler.join(1e100)
# 再次检查进程池,并等待进程退出
if pool and hasattr(pool[0], 'terminate'):
debug('joining pool workers')
for p in pool:
if p.is_alive():
# worker has not yet exited
debug('cleaning up worker %d' % p.pid)
p.join()
pool.join
这个方法逻辑简单粗暴。直接依次执行每个handler线程以及pool中子进程的join
注意这里的join是没有超时时间的,会block住signal。
此处也是会导致ctrl-c后进程无法退出的一个原因。
如果子此时调用的是close方法,并且进程不能正确处理异常,导致一些进程的执行结果没有设置到ApplyResult,就会导致
pool._cache永远不为空,此时worker handler就永远无法退出。主进程就会一直block在self._worker_handler.join()
def join(self):
debug('joining pool')
assert self._state in (CLOSE, TERMINATE)
debug('joining worker handler')
self._worker_handler.join()
debug("joining task handler")
self._task_handler.join()
debug("joiningg result handler")
self._result_handler.join()
debug("joining pools")
for p in self._pool:
p.join()