最近复习,遇到go内存模型的问题,心中一直以为硬件是会保证缓存和内存一致性的。不过看了不少例子有很多困惑,关于happend before之外的困惑。之后就又查了不少硬件内存模型的文章。这里就记录一下一些不错的文章,再对几个例子做一些硬件体系上的汇总,不再详细说明go的内存模型了,毕竟关于go内存模型的文章有很多。
推荐先阅读的文章:
- 缓存一致性(Cache Coherency)入门: 这篇文章讲述了内存一致性协议,以及简单的缓存知识。个人感觉作为基本入门阅读很不错,解决了不少疑惑。
- 每个程序员都应该了解的 CPU 高速缓存: 这篇文章讲的比较细,cache line的抽象逻辑图,和内存的映射策略。缓存协议。以及一些对缓存的测试都有讲。想要更深了解细节的是不错的选择。
看完这些,我们首先看一些一般性的内存模型例子:
| thread 1 | thread 2 |
|---|---|
| x = 1; | while (done==0) {}; |
| done = 1; | print(x); |
上面的代码结果是可以输出0吗?
- 在x86系统上使用汇编:不会。 原因x86有较强的顺序一致性保证(sequential consistency),cpu会确保输入指令和输出结果在顺序上是一致的。也就是done对外(对其他核或者cpu线程)可见的时候,x也必定可见。
- 在arm/power系统上使用汇编:可以输出0。arm是弱一致性保证,有乱序执行以及store buffer的存在,会出现done对外可见在x对外可见之前的情况。他们有提供其他cpu指令供开发人员使用,达到保证一致性的目的。(memory barrier and fence 相关指令)
- 很多c编译器,即使在x86:会出现。原因是编译器的指令重排。注: 还有说线程2甚至不会退出的,这点我还没理解~_~。
测试的go代码:
下面贴出它在nanopi(linux arm)上的执行结果:
pi@nanopi:home/pi$ ./csub -run ./sub
detected 1 run times 2502
detected 2 run times 12099
detected 3 run times 20173
detected 4 run times 21717
detected 5 run times 24605
detected 6 run times 26428
detected 7 run times 27316
detected 8 run times 32485
detected 9 run times 36591
detected 10 run times 37471
detected 11 run times 40090
detected 12 run times 45609
detected 13 run times 54260
detected 14 run times 54378
detected 15 run times 55655
detected 16 run times 56905
detected 17 run times 58546
detected 18 run times 60083
detected 19 run times 60228
detected 20 run times 60790
相同的测试时长,mac上无任何输出
| thread 1 | thread 2 |
|---|---|
| x = 1 | y = 1 |
| r1 = y | r2 = x |
上面代码是否会出现 r1 == r2 == 0呢?
- 顺序一致性系统:不会。
- x86:可以。原因是什么呢,当线程1和2运行在两个核心的时候,在cpu的流水线内部,x和r1,y和r2的顺序是无法保证的,是否和上面1的例子冲突了呢?并没有,cpu会保证输出结果的一致性,但不保证执行顺序一致。这里r1获取y的操作结果会排在x获取1之后,但是因为执行乱序的原因,两个核心分别先执行r1和r2的赋值,再执行x和y的赋值,那么结果就会是r1 == r2 == 0。
下面来个图示:
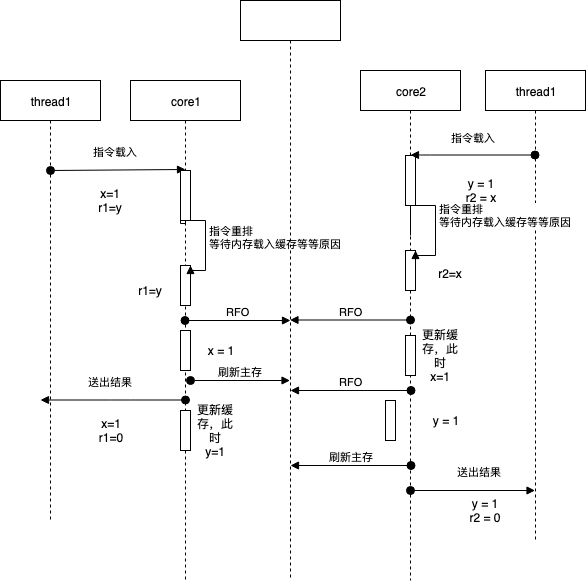
此时再返回到go内存模型,这个时候就已经是语言层面提供的内存一致性保证了(由编译器保证),脱离了硬件层面的差异。总之,Don’t be clever,写代码老老实实把可能会并发读写的变量串行化访问就好了。
参考文章: